
.jpg)
全栈学习日记1-基于FASTAPI的增值税发票批量识别✨
项目地址:https://github.com/FineHow/invoice_ocr
🚩项目怎么启动?
git clone https://github.com/FineHow/invoice_ocr.git
后端启动
#后端环境配置
cd backend
#创建虚拟环境
python -m venv venv
#激活虚拟环境
venv\Scripts\activate
#安装环境
pip install -r requirements.txt
cd..
#启动后台
uvicorn main:app --host 0.0.0.0 --port 8000前端启动
cd frontend
npm install
npm run dev
🚗后端部分
架构:使用python3.12.4 fastapi架构
因为更适合高并发接口情况,项目需要单独的接口服务,所以选择了fastapi架构
关于选择什么架构?以下是我搜索的架构总结,希望之后有机会可以接着学习Flask和Django
关于FastAPI架构:
FastAPI框架
1. 特点:
高性能: 基于Python的异步框架Starlette和高性能JSON处理库Pydantic,旨在提供高性能并支持异步编程。
以API为核心: FastAPI主要面向构建RESTful API服务,特别用于微服务架构开发。
现代编程模式: 使用Python的类型提示(Type Hints)来自动生成请求验证、响应模式和交互文档(如Swagger UI)。
适用于: 构建快速、高性能的API服务,数据验证和交互文档需求强的项目。
2. 优势:
自动生成API文档(如Swagger和Redoc),极大提高了开发时的效率。
原生支持异步编程,适合高并发场景。
类型提示增强了代码的可维护性和开发体验,同时还能自动校验数据。
性能在Python框架中表现非常优秀。
3. 劣势:
面向API开发,相较于Django,缺少部分Web开发功能(如模板渲染)。
生态系统相对较小,刚出现不久,有些领域扩展库可能不如Django完整。
学习异步编程需要一定额外理解成本。
搭建过程:架构的优化与动态配置
fastapi我没有使用脚手架搭建,是直接手搓的,锻炼一下自己对整体后端的认识,第一步的初步搓架构十分粗糙,但我觉得也是很有必要回顾一下的。
我的第一代文件目录如下:【可以在github的devmain分支中查阅】
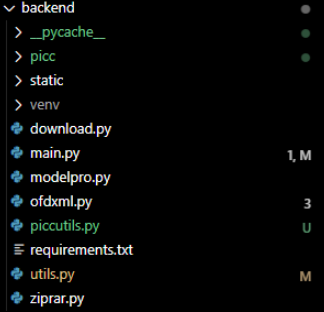
其实就是直接写在目录下了,直接写了一个main.py作为主函数,然后创建了一个虚拟环境venv,写了一个requirements.txt放环境,方便搭建。其余所有的调用全部是直接写方法函数进去,接口写在了main.py里,主方法放在了utils.py里,其他方法也是直接扔。这样确实不好管理环境变量,也没有做好文件管理,模块管理。
然后我们再来看一下这个主函数里写的内容,也是一塌糊涂:
import logging
import os
from fastapi import FastAPI, UploadFile, Form
from fastapi.responses import FileResponse
import fitz # PyMuPDF
import requests
import openpyxl
import aiofiles
import uuid
from pathlib import Path
from backend.utils import perform_ocr, save_excel, extract_invoice_data, umi_ocr,umi_invoice_data
from backend.modelpro import extract_invoice_data_with_gemma,test_gemma_chat
from backend.download import save_excel
from backend.ziprar import handle_zip_uploaded
from fastapi.middleware.cors import CORSMiddleware
from PIL import Image
import numpy as np
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
OCR_API_BASE_URL = os.getenv("OCR_API_BASE_URL")
app = FastAPI()
# health检查
@app.get("/")
async def health_check():
try:
response = requests.get(OCR_API_BASE_URL + "/")
return {"message": response.json()}
except Exception as e:
return {"error": str(e)}
# 批量上传并处理发票
@app.post("/process_invoices/")
async def process_invoices(files: list[UploadFile], language: str = Form("chi_sim")):
output_dir = Path("backend/static/")
output_dir.mkdir(parents=True, exist_ok=True) # 确保路径存在
# 批量保存 PDF 到临时文件夹并从PDF提取图像
extracted_data = []
# 处理 ZIP 文件
for file in files:
if file.filename.endswith('.zip'):
# 保存 ZIP 文件到指定目录
unique_filename = f"{uuid.uuid4()}_{file.filename}" # 确保文件名唯一
zip_path = output_dir / unique_filename
async with aiofiles.open(zip_path, mode="wb") as f:
await f.write(await file.read())
# 调用解压函数
handle_zip_uploaded(zip_path, output_dir)
# 遍历解压后的文件夹,找到所有 PDF 文件
extracted_files = [
p for p in output_dir.iterdir() if p.suffix == '.pdf'
]
for pdf_file in extracted_files:
# PDF 文件后续处理逻辑(转换 PDF 页面到图像等)
pdf_path = pdf_file # pdf_file 是解压后的 PDF 文件路径
pdf_document = fitz.open(pdf_path)
for page_number in range(len(pdf_document)):
page = pdf_document[page_number]
mat = fitz.Matrix(5, 5) # 放大倍数
pix = page.get_pixmap(matrix=mat)
# 保存页面图像为临时文件
temp_image_path = output_dir / f"{pdf_file.stem}_page_{page_number + 1}.png"
pix.save(temp_image_path)
# 调用 OCR 处理图像
ocr_result = umi_ocr(temp_image_path)
ocr_result = umi_invoice_data(ocr_result)
print(f"处理结果: {ocr_result}")
extracted_data.append({
"file": pdf_file.name,
"page": page_number + 1,
"text": ocr_result
})
# 删除图像文件
temp_image_path.unlink()
pdf_document.close()
# 删除 PDF 文件
pdf_path.unlink()
elif file.filename.endswith('.pdf'):
# 如果是 PDF 文件,单独处理
pdf_path = output_dir / file.filename
async with aiofiles.open(pdf_path, mode="wb") as f:
await f.write(await file.read())
pdf_document = fitz.open(pdf_path)
for page_number in range(len(pdf_document)):
page = pdf_document[page_number]
mat = fitz.Matrix(5, 5)
pix = page.get_pixmap(matrix=mat)
temp_image_path = output_dir / f"{file.filename}_page_{page_number + 1}.png"
pix.save(temp_image_path)
ocr_result = umi_ocr(temp_image_path)
ocr_result = umi_invoice_data(ocr_result)
print(f"处理结果: {ocr_result}")
extracted_data.append({
"file": file.filename,
"page": page_number + 1,
"text": ocr_result
})
temp_image_path.unlink()
pdf_document.close()
pdf_path.unlink()
else:
return {"error": "文件格式错误,请上传 PDF 文件或 ZIP 文件!"}
# 保存数据到 Excel 并提供下载链接
excel_file_path = output_dir / "extracted_data.xlsx"
# save_excel(extracted_data, str(excel_file_path))
body = {
"message": "success",
"code": 200,
"status": 200,
"data":{
"extracted_data": extracted_data,
"excel_file_path": str(excel_file_path)
},
}
return body
# 提供Excel下载
@app.get("/download/{file_name}")
async def download_file(file_name: str):
file_path = Path("backend/static/") / file_name
if file_path.exists():
return FileResponse(path=str(file_path), filename=file_name, media_type="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet")
return {"error": "File not found"}主要是几个问题,这边反思一下
环境变量没有动态配置,一个个load相当糟糕
api不好好做统一管理,全部挂在app下面后期不好拓展
uuid只做一个,下载没做
工具函数接口文件混在一起,文件管理相当混乱
所以我决定痛改前非,修改我的架构,使之更加清晰可靠,并且改掉之前的坏毛病:
INVOICE_OCR/
├── backend/==
│ ├── api/ # 存储所有API接口模块
│ │ ├── v1/ # 按版本分组 API
│ │ │ ├── invoice.py # ocr识别相关接口
│ │ │ ├── download.py # 下载相关接口
│ │ │ ├── iaimodel.py # AI模型相关接口
│ ├── core/ # 主逻辑代码
│ │ ├── config.py # 配置管理模块(动态加载 .env)
│ │ ├── utils.py # 工具函数模块
│ │ ├── download.py # 下载函数模块
│ │ ├── modelpro.py # 模型函数模块
│ │ ├── ofdxml.py # 解码函数模块
│ │ ├── ziprar.py # 解压缩函数模块
│ ├── static/ # 静态文件
│ ├── main.py # 应用入口
│ ├── requirements.txt # 后端依赖
这样的架构是否清晰了许多呢?首先把接口统一放到api下,然后把工作函数和动态环境变量配置统一放入core下管理。
然后值得一提的是环境变量的动态管理,在config.py里用类函数做环境定义:
import os
from dotenv import load_dotenv
# 动态加载 .env 文件
env = os.getenv("APP_ENV", "development")
if env == "production":
load_dotenv(".env.production")
else:
load_dotenv(".env.development")
class Settings:
UMIOCR_API_BASE_URL = os.getenv("UMIOCR_API_BASE_URL")
OCR_API_BASE_URL = os.getenv("OCR_API_BASE_URL")
OLLAMA_PROXY_URL = os.getenv("OLLAMA_PROXY_URL")
APP_HOST = os.getenv("APP_HOST", "127.0.0.1")
APP_PORT = int(os.getenv("APP_PORT", 8000))
LOG_LEVEL = os.getenv("LOG_LEVEL", "DEBUG")
RELOAD = os.getenv("RELOAD", "True") == "True"
# 全局 Settings 实例
settings = Settings()🚕前端部分
前端架构:使用vue3+element-plus+node20
因为我比较擅长vue哈,react架构其实也很好,但是一般如果我使用react架构的话,会习惯前后端都统一使用ts去做开发,这样前后端的语言一致会让人觉得很舒适,虽然这个vue2是以前用的,但是他的框架十分清楚,所以在这里用vue3进行搭建,并且vue3我们可以一键脚手架辅助搭建,十分的方便